
During early summer 2020, we benchmarked recent GPU models available on Nef cluster for deep-learning using ResNet-50 model training, with ImageNet 2021 dataset and TensorFlow 2.0 official implementation. Please find here a summary of the results and lessons learnt.
The different Nvidia GPU models tested are :
- GTX1080Ti a GeForce (consumer) card from 2017-03, Pascal generation
- RTX2080Ti a GeForce (consumer) card from 2018-09, Turing generation
- RTX6000 a Quadro professional card targeting graphics and deep-learning from 2018-08, Turing generation
- V100 SXM2 a Tesla high end professional card targeting deep-learning and HPC computation from 2017-12, Volta generation
- T4 a Tesla entry level professional card targeting deep-learning with a high power efficiency from 2018-09, Turing generation
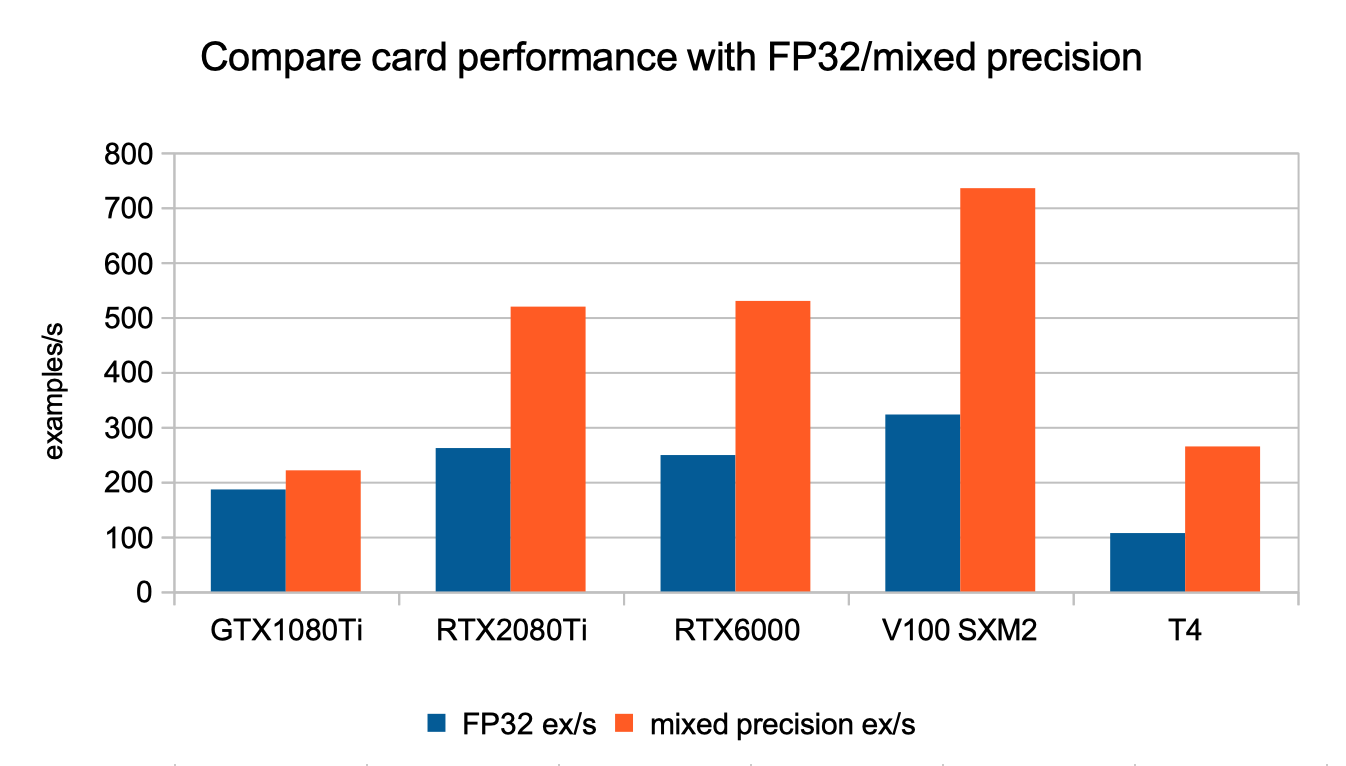
First we compared the different GPU card models using a batch size of 64 for our data samples and both the default FP32 (32 bits floating point) and mixed precision (16/32 bits) for training.
All models except older GTX1080Ti offer hardware support for half precision, which roughly results in a x2 performance increase when using mixed precision, with power efficiency gain in the same range. Also in our tests model convergence speed is little impacted, though we only tested on a small number of epochs. With automatic mixed precision making it easy to use, mixed precision training should be used in most cases.
Comparing card models, at no surprise : V100 high end card has the top performance ; RTX6000 and RTX2080Ti which have close hardware architecture except memory size have almost the same performance.

Data sample batch size is a commonly used parameter to tune performance for deep learning training on GPU. The bigger the batch, the more data samples the model trains with on the GPU without data transfers from and to the host server. Batch size is limited by the GPU memory size minus the memory footprint of the model and its computation variables.
As expected, we observed a performance gain when increasing batch size, though it becomes minimal when data transfer to and from the GPU takes far less time than training on samples. Using the highest possible batch size for a model and GPU usually gives the best performance. Nevertheless, the observed gains suggest it is not worth buying a more expensive / higher memory GPU only for that purpose.
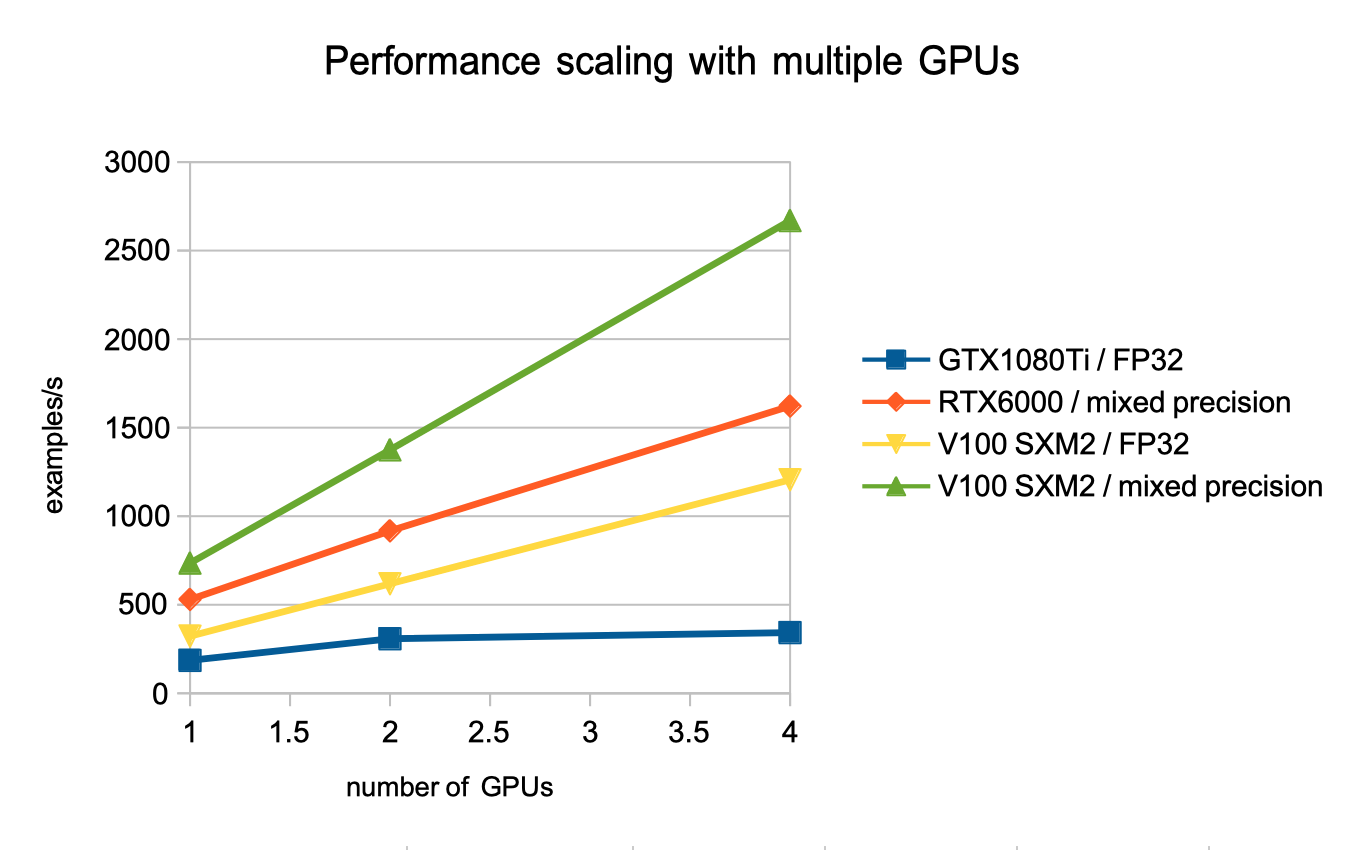
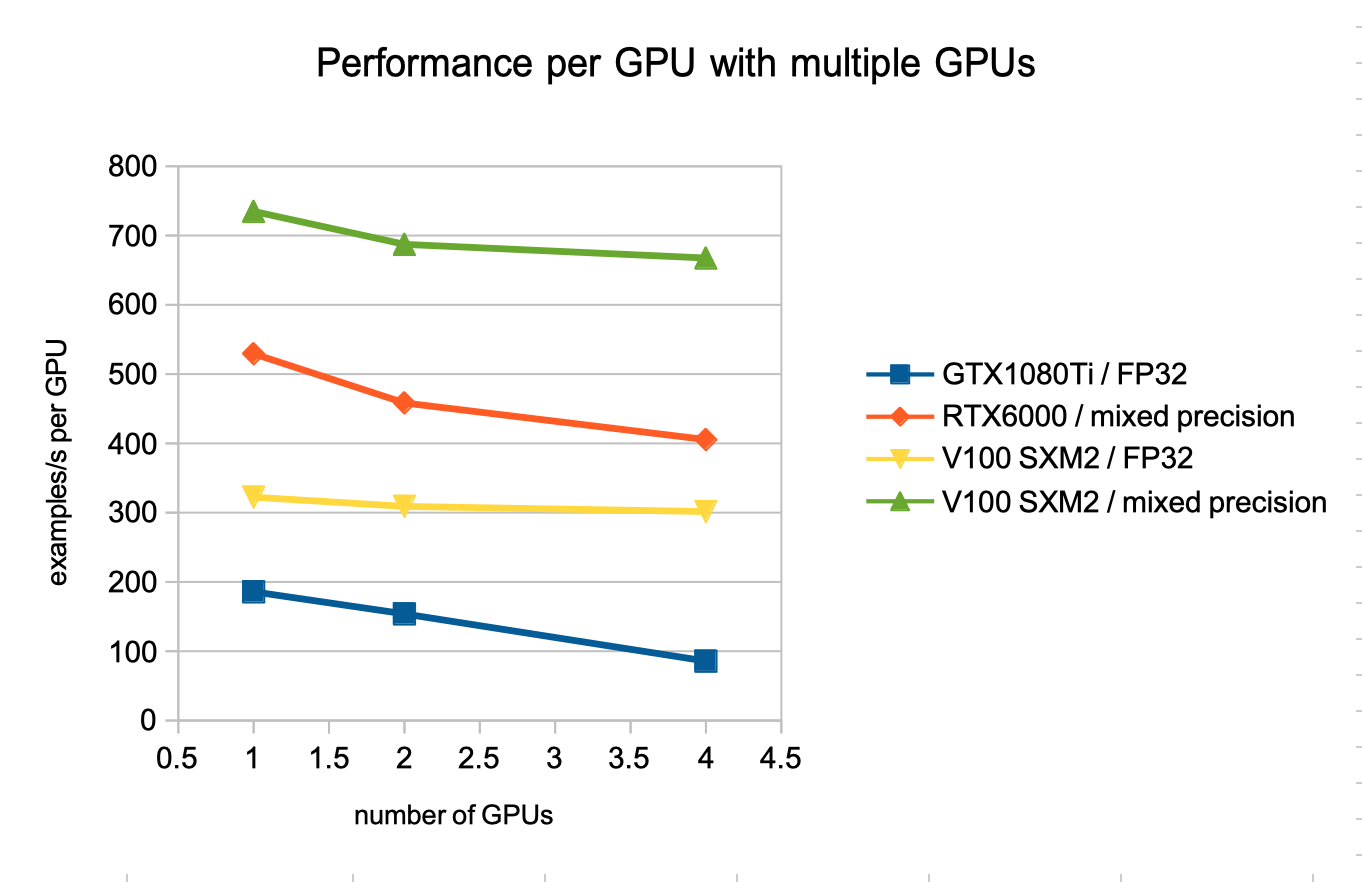
We then tried to scale training to multiple GPUs on the same host, scaling the batch size in the same proportion.
In our test, GTX1080Ti scaled poorly. V100 was the nearest from ideal linear scaling, with the help of the NVLink (SXM) between the node’s GPUs.
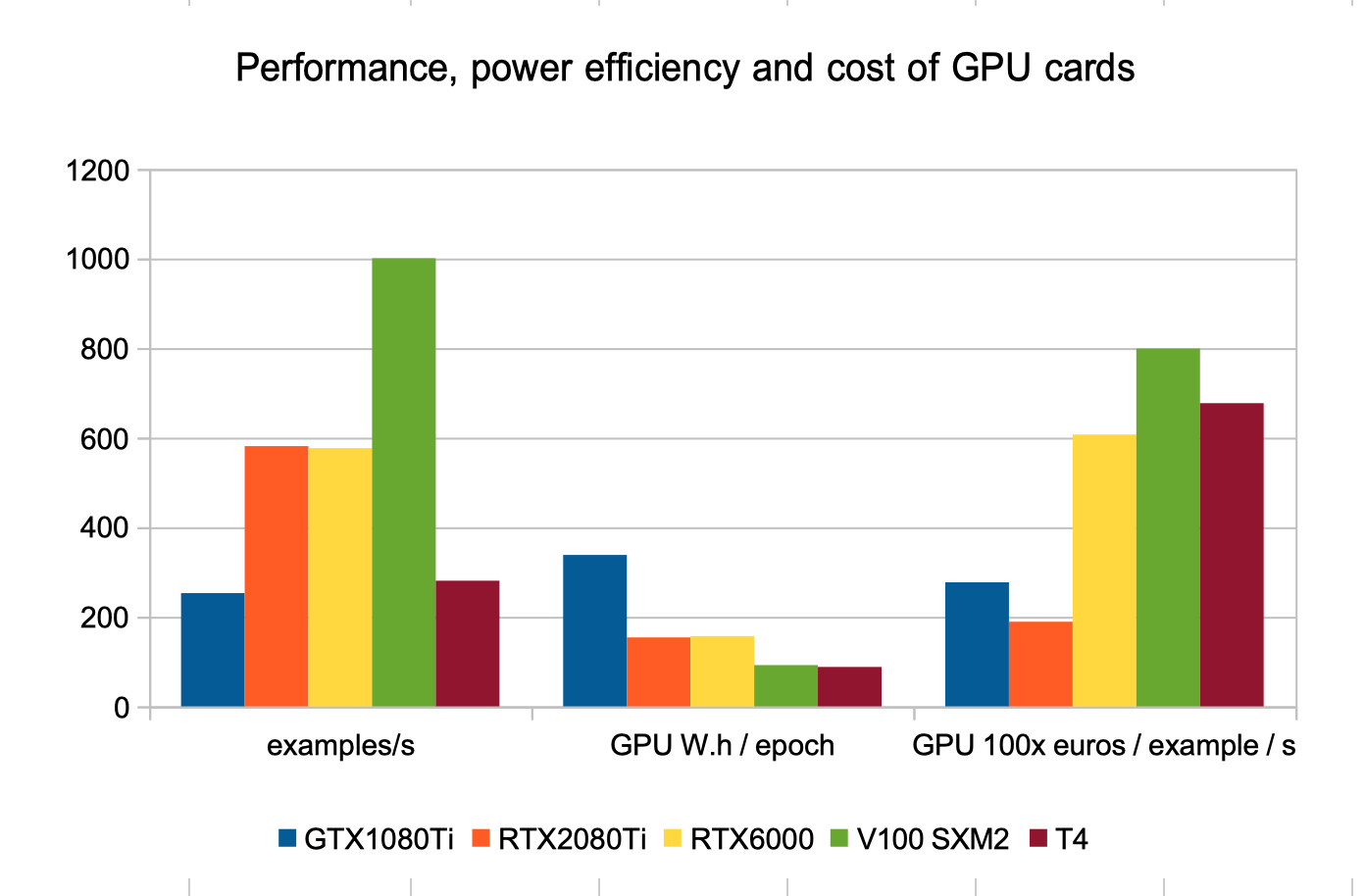
Finally we tried to get the best performance out of each card by using mixed precision training and maximum possible batch size.
In terms of raw performance, 32GB memory high end V100 increased the lead over other cards, all in the 11-24GB range.
More interesting, we estimated the cost of the GPU cards for education/research divided by the training speed (100x euros / example / s) : the lower, the better (more money efficient card). Please note this only includes the GPU cost, considering the full investment cost or the TCO would probably reduce the differences.
As expected, consumer GPUs (GeForce) have the higher training speed per euro for this test. Nevertheless, a closer comparison between GeForce RTX2080Ti (11GB memory) and Titan RTX, Quadro RTX6000 (24GB memory) and RTX5000 shows most of the difference comes from the price of the GPU memory. Thus it is a good choice to favor professional cards over consumer cards, but only buy a higher memory GPU if you need to train a bigger model that would not fit in another card’s memory.
Finally we estimated the power efficiency of the GPU cards (W.h per training epoch) : the lower, the more power efficient. Please note this does not include the full imputable power consumption of the training (server, cooling) that would probably lower the differences.
In terms of power efficiency, the general purpose computation (GPGPU) Tesla cards (T4 and V100) are the more efficient. The older GTX1080Ti lags behind, mainly because of the lack of hardware support for mixed precision.
From a sustainable development point of view, using mixed precision training (versus FP32) gives an obvious gain. When a computation is not urgent, using the power efficient and relatively cheap T4 cards is also advisable.