
Ecological impact of IT is an increasingly important matter. This is why estimating the impact of a computation is useful, both for assessing the cost of a research activity or designing efficient methods. Power consumption and carbon emissions of a computation are commonly used metrics, as this is a more simple approximation than taking into account the full life cycle of IT infrastructures.
We tried several simple ways of roughly estimating the power consumption and carbon impact of training a ResNet-50 deep-learning model on Nef cluster. This post presents them along with the results obtained. Please note this is only meant to be a first step in the field, not a detailed study, but they’ll hopefully catch interest of some Inria Sophia teams to prepare next steps.
These tests were done by SED-SAM and are related to Inria Sophia sustainable development commission (CLDD) efforts, and its DD newsletter #5 and newsletter #6 (to be published when this post was written),
Testbed
For the tests we used :
- the official model implementation of ResNet-50 from tensorflow 2.0
- mixed-precision (FP16/FP32)
- the dataset ImageNet ILSVRC2012
- either a server Dell R740 with 2x CPU Intel Xeon 4110, 96GB RAM, 3x GPU Nvidia Tesla T4, CentOS 7.6
- or a server Dell T640 with 2x CPU Intel Xeon 4214, 192GB RAM, 4x GPU Nvidia Quadro RTX6000, CentOS 7.6
- for the tests we choosed to book the full server (to ensure isolation from other computations) but used only one GPU
Tesla T4 is a low power GPU (70W) marketed by Nvidia (back in 2019) as their most power efficient accelerator. Quadro RTX6000 is a powerful cost effective GPU for deep learning, with a maximum consumption (TDP) of 260W.
Depending on the test we estimated or measured power consumption of some hardware elements (GPU, CPU, RAM) or of the full server. To compute a full power consumption, a Power Usage Effectiveness factor (PUE) was applied to take into account the cooling system of the server room, etc. PUE for Inria Sophia server room estimate is 1.65 (2018 numbers). Depending on the test, carbon intensity of electricity (CO2 g / kW.h) was either automatically chosen by the tool depending on geographical region (France) or we used the 2018 average estimate from the French Environnement Agency (ADEME) of 57.1 CO2 g / kWh for electricity produced in France.
Measurement methods
We used the following different ways for estimating power consumption and carbon impact :
GPU manual measure :
- launch a training and record nvidia-smi output every 5 seconds during computation to measure GPU power consumption
- do not take into account CPU, RAM and other power consumption
- apply manually PUE factor and carbon intensity factor to the GPU power consumption measured to compute kWh / epoch and g CO2 / epoch
Online estimator :
- launch a training with the time command to measure execution time and estimate CPU usage
- use green-algorithms.org online estimator which computes kWh and g CO2, compute a per epoch mean
- estimate the consumption for one GPU, considering it was fully used during the computation (no scaling factor) and had no associated usage of memory (this is counted with CPU)
- estimate the consumption for CPU, with execution time and number of cores from time command results, considering the cores were fully used during the computation (no scaling factor), hinting all the RAM available when booking a GPU on the node was used (24GB with the T4 node, 48GB with the RTX6000 node)
Measure tool :
- use experiment-impact-tracker tool, installed on Nef for these tests. It estimates the GPU, CPU and RAM consumption of one computation on a shared machine with a mix of sample measures and estimation for imputing a share of the activity to a specific computation.
- cut/paste the 4 lines of code in the Python code of the ResNet-50 training to activate tracking at launch time. The tool currently supports only Python.
- launch a training
- generate a report with the create-compute-appendix script of the tool which includes kWh and g CO2, as explained in the documentation
- compute a per epoch mean of these numbers
Server measure :
- launch a training with the time command to measure execution time
- during the training, record the total server power consumption as estimated by the Dell iDRAC server management card with ipmi-get request every 5 seconds. This method is currently not available to Nef users, it requires administrator access
- apply manually PUE factor and carbon intensity factor to the GPU power consumption measured to compute kWh / epoch and g CO2 / epoch
Server measure minus idle :
- use the same method as in server measure, but substract the estimated power consumption of the server when it is up and running but idle. This measures the power overhead due to the training.
- sample measures gave a minimum 156W for R740 + 3 x T4 when idle, and a minimum 234W for T640 + 4x RTX6000. This is all but negligible, and this is why Nef puts most unused nodes in standby mode (server off, only management card is active)
Results and comments
Results are summarized in the following diagrams :
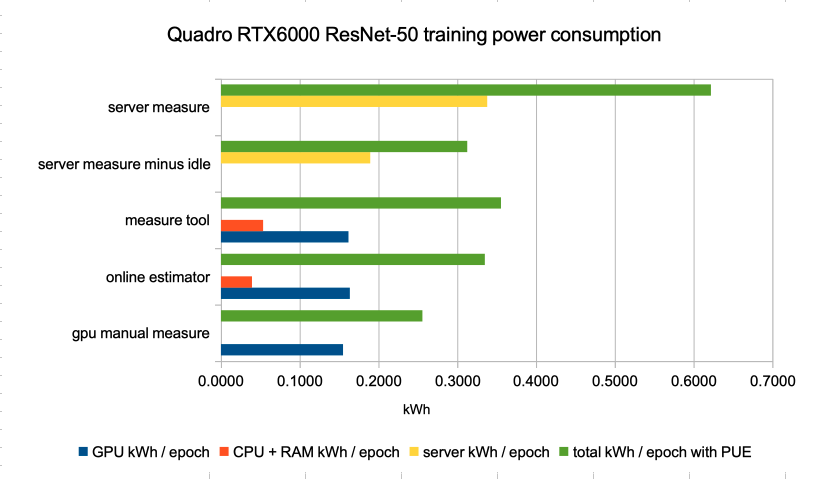
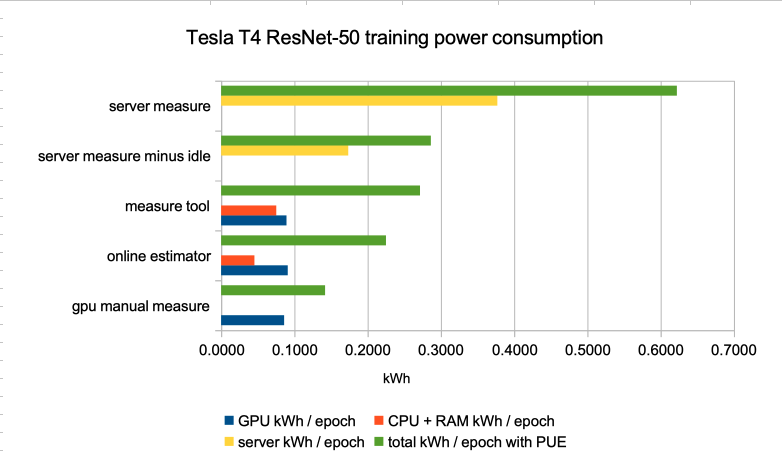
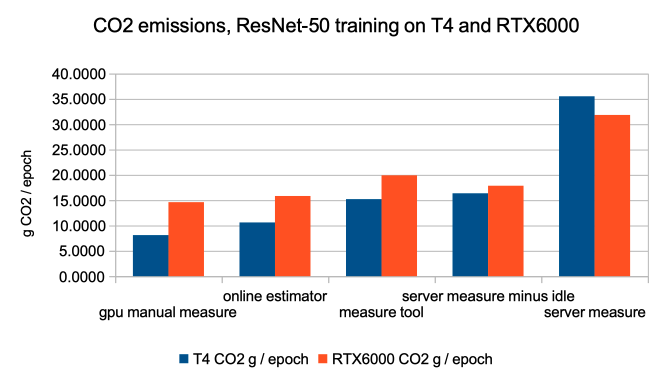
A few comments on these results :
- GPU consumption estimates are rather near with the different methods. At no surprise, this is the easiest part to estimate insofar as we trust nvidia-smi
- CPU consumption (and to a lesser extend RAM consumption, when the method shows separate numbers for the two) is far from negligible. Estimation shows more difference depending on the method than for GPU, which may mean real measures are useful for that part.
- server measure minus idle total kWh / epoch is not so far from those of measure tool and online estimator, which gives some confidence in methods based on GPU/CPU/RAM measure or estimation for computing power consumption overhead.
- consumption of a the idle server represents a great share of the power consumption. This would represent a smaller part if our testbed used all the capabilities (GPU) of the server.
- il also means the relative efficiency gain with a low power GPU (T4) is less than the GPU would indicate (70W versus 260W).
Conclusion on suggested use cases for these methods :
- GPU manual measure and online estimator permit very quick rough estimates of the impact of a training
- measure tools permit relative efficiency measures of several training, for example to compare models, implementation, accelerators. It is rather simple for a Python code with the experiment-impact-tracker. A nice test would be to redo the same training on a dedicated and then on a shared server, to ensure the measure tool gives accurate estimates also on a shared server.
- server measures give a more accurate view of the total power or carbon impact of a training, but it also means the results are very infrastructure dependant. Such measures also require booking full server and support by the platform.