
GPU cards were originally designed for graphics. Over years, their powerful massively parallel architectures became used for AI and HPC computations. High level frameworks, like Tensorflow or Pytorch in the deep-learning field, permitted wide adoption by hiding complexity from lower programming layers like CUDA.
Now OpenACC or OpenMP permit easy parallelization of your C,C++, Fortran source code and its offloading to an accelerator such as a GPU card. Offloading means that your code will be run in part on your machine’s CPU and in part on the GPU.
For that to happen you’ll need :
- a GPU card with error correction memory (ECC). Without ECC, undetected memory bit value changes may occur while your code is running. While this is considered acceptable for graphics (a bad pixel) or deep-learning (iterations will compensate), this is usually not for numerical simulations. But most consumer GPUs, like GeForce cards on the laptops, don’t have ECC. Too bad. So you can play with offloading on your laptop, but don’t trust the results unless you checked your GPU configuration.
- a compiler with support for OpenACC and GPU offloading such as PGI or gcc. Some recent Linux distros have pre-built packages, for example on a Fedora 31 : yum install gcc-offload-nvptx (from the so-fedora repo).
- adding support for OpenACC in your source code by identifying where data parallelism stands and adding information for the compiler to exploit it with #pragma acc (C/C++) or !$ACC (Fortran) directives. The source code itself is unchanged, only a few preprocessor-like lines are added.
- re-compiling your code.
Inria Sophia Antipolis computation platform – Nef is now ready for OpenACC offloading. It includes :
- several Nvidia GPU cards with ECC activated : Tesla V100, Quadro RTX6000, Tesla T4, Tesla K80.
- PGI and gcc versions with OpenACC offloading support to Nvidia GPUs (NVPTX).
- FAQs explaining how to use it with gcc and PGI.
OK nice, but is there really a performance gain ? We tested OpenACC offloading to Nvidia GPU with the matrix multiplication sample code from gcc OpenACC page.
First test is comparing a 3000×3000 matrix multiplication without and with OpenACC NVPTX offloading, with types double and float, with compilers gcc and pgi, with GPU V100 T4 and RTX6000.
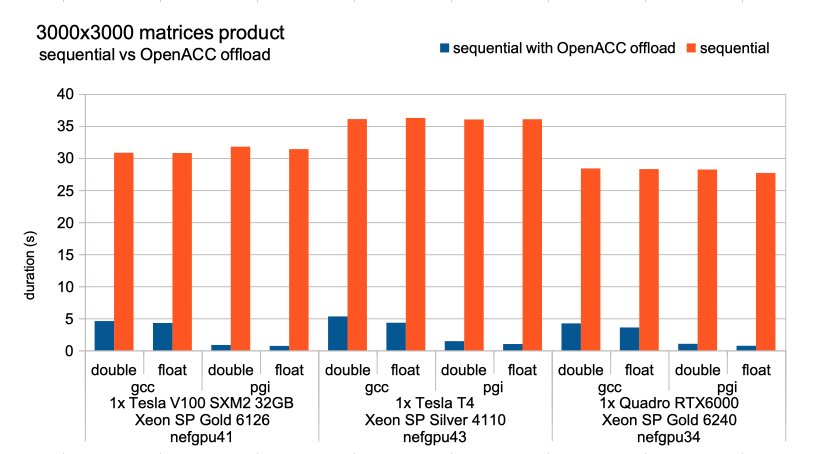
Speed gain between sequential code execution (1 CPU core) and offloading (1 CPU core + 1 GPU) is in the x6 – x45 range. While gcc and PGI are equivalent for sequential code, PGI is far ahead for code with offloading : gcc documentation indicates that OpenACC support is not yet performance optimized.
Second test is a 9000×9000 matrix multiplication with OpenACC NVPTX offloading, with types double and float, with compilers gcc and pgi, with GPU V100 T4 and RTX6000.
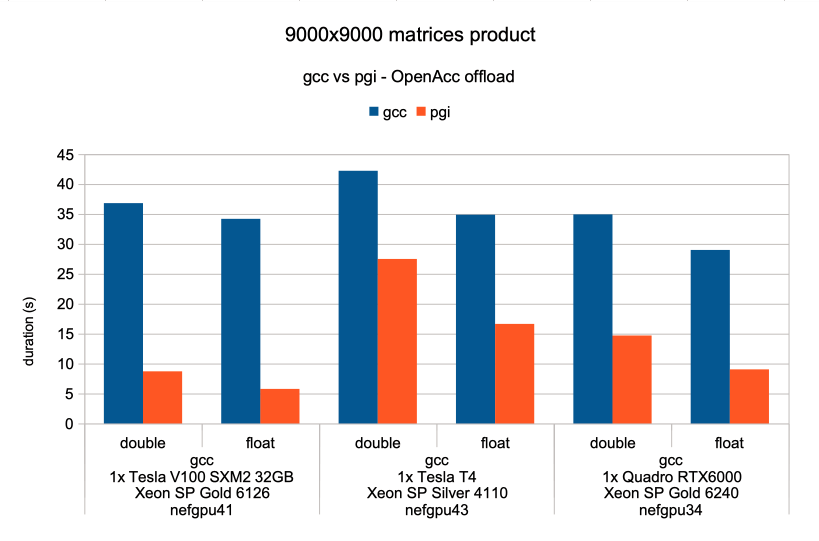
PGI performance gain over gcc is in the x1.5 – x6 range. While gcc performance is barely equivalent on those recent (Volta/Turing) GPUs, PGI better matches the nominal GPU performance specs ; for example it gives a x3 perf ratio between V100 and T4, as marketed by Nvidia.
The Nvidia profiler tools are useful for analyzing and tuning your code. Please note that CUDA 10.0 (current version on Nef) still uses the legacy nvprof / nvvp tools, while CUDA 10.1 adds support for newer nsys / nsight. On Nef to profile a code named matrix_mult_binary and view the results with the GUI :
module load cuda/10.0
nvprof -o resfile.nvvp ./matrix_mult_binary
nvvp &
# in nvvp GUI : File > Open : resfile.nvvp
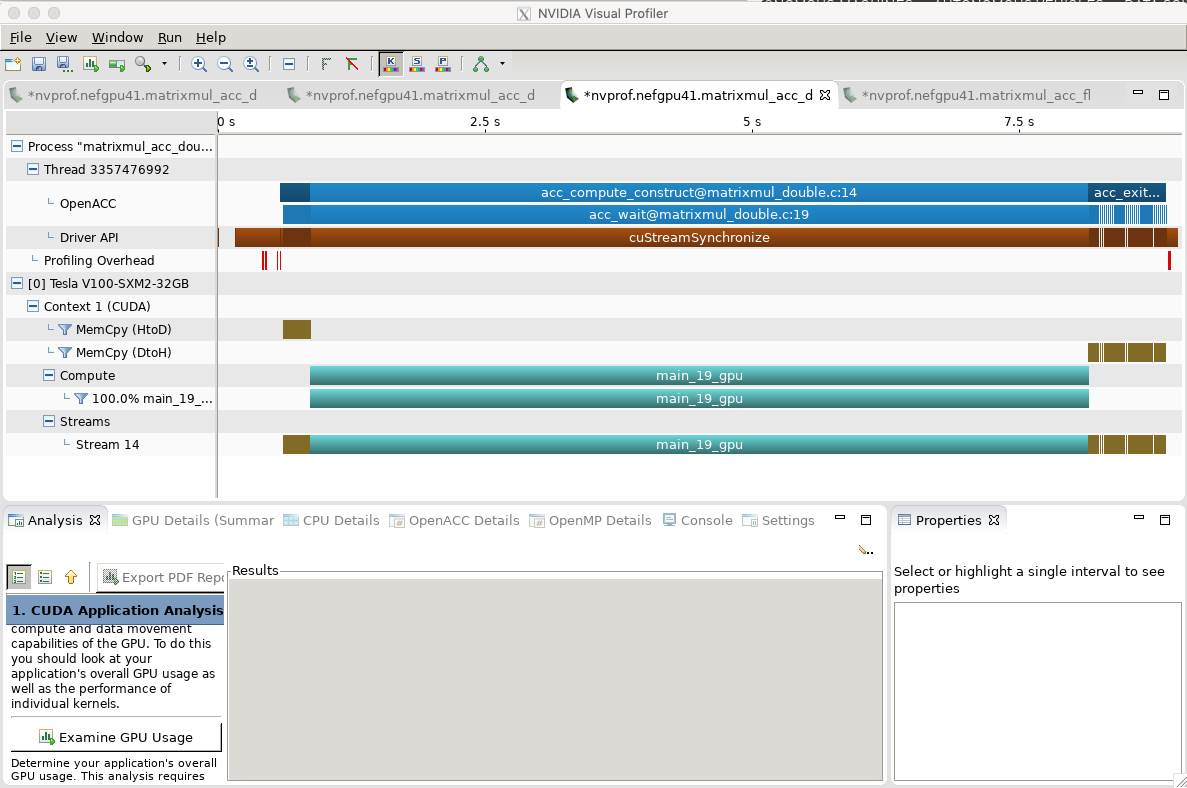
For all “test 2” cases (9000×9000 matrix multiplication), profiling shows that >85% of the elapsed time is for execution of the offloaded code on the GPU (cuStreamSynchronize), while <5% in the data copy to/from the GPU (CUDA memcpy HtoD and DtoH). All data transfers to/from the GPU occur before and after computation on the GPU. This is coherent with the #pragma acc kernels copy in the test code, which also does not exceed the GPU memory. Thus our “test 2” cases really measure the offloaded code execution performance on the GPU.
Conclusion is that OpenACC GPU offloading permits huge performance gains (especially with PGI), hopefully with a reasonable effort. Finer optimization can nevertheless become a complex mix of coding, compiler and infrastructure.
Real world codes probably want to combine CPU parallelization (OpenMP) and offloading, datasets exceeding the GPU memory. We did not test that yet.