
CMUSphinx, where CMU stands for Carnegie Mellon University, is an open source toolkit for speech recognition. This proof of concept, aims at using speech instead of a mouse to trigger transitions within a state machine, and have a visual feedback of it.
Speech recognition
Speech is a continous audio stream where one can define more or less similar classes of sounds called phones. However, the acoustic properties of a waveform corresponding to a phone can vary greatly depending on many factors: microphone, speaker, style of speech. Instead of phones, one consider diphones, parts of phones between two consecutive phones. In practice three regions of different nature can easily be found: the first depending on the previous phone, the middle phone which is stable and the last phone which depends on the following phone, they are triphones. Such objects are called senones.
The common way to recognize speech is the following: a waveform is split into utterances by silences, then senones are tried to be recognized, using a feature vector, that is, 39 numbers extracted for each frame of 10 milliseconds, and a model, that describes some mathematical object that gathers common attributes of spoken words. In practice, the audio model of a senone is a gaussian mixture of it’s three states, the most probable feature vector that is matched using hidden markov models.
According to the speech structure three models are used in speech recognition to do the match: an acoustic model contains the acoustic properties for each senone, a phonetic dictionary that contains a mapping from words to phones, and a language model which is used to restrict word search.
Software
The CMUSphinx toolkit is made up of libraries and tools, the one we will use are sphinxbase, a support library that contains the foundations of speech recognition and pocketsphinx, a lightweight recognizer library written in C language. Each library comes with autotools for building, in this proof of concept, we have just specified a specific prefix in order to easily explore what is being installed.
% ./configure --prefix=/home/.../Development/sphinx % make % make install
Next for threading purposes and state machine implementation as well as graphical feedbacks, we will use a Qt installation where the version >= 5.0.
Use case
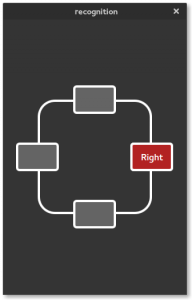
For this proof of concept, we have built a dictionnary and a language model using Sphinx’ online generation tool at http://www.speech.cs.cmu.edu/tools/lmtool-new.html, using the corpus file which contains the four words that we want to be able to match.
top bottom right left
The result is a .lm language model and a .dict dictionnory file that we provide to our executable on the command line usinf the -lm and -dict arguments.
The words, will be used to trigger a transition that will move the rectangle to its proper place.
Implementation
Let’s start with a very usual skeleton for a Qt application.
// Version: $Id$
//
//
// Commentary:
//
//
// Change Log:
//
//
// Code:
#include <QtCore>
#include <QtDebug>
#include <QtQuick>
#include <QtWidgets>
#include "sphRecognizer.h"
int main(int argc, char *argv[])
{
QApplication application(argc, argv);
sphRecognizer recognizer(argc, argv);
recognizer.start();
QQuickView *view = new QQuickView;
view->engine()->rootContext()->setContextProperty("recognizer", &recognizer);
view->setSource(QUrl::fromLocalFile("main.qml"));
view->show();
view->raise();
int status = application.exec();
recognizer.terminate();
recognizer.wait();
return status;
}
//
// main.cpp ends here
It declares a QtQuick view that is shown presenting the contents of the main,qml file that we will look later on. The only original thing is the sphRecognizer instance, which is a recognizing thread of our own, which is built on top a shpinx binary – sphinx continous – tweaked to run within an aquisition thread. This recognizer is bound to the QML side as a root context property, making its signals and slots available with javascript within a QML implementation. Here is its declaration.
// Version: $Id$
//
//
// Commentary:
//
//
// Change Log:
//
//
// Code:
#include <sphinxbase/ad.h>
#include <sphinxbase/err.h>
#include <sphinxbase/cont_ad.h>
#include <pocketsphinx.h>
#include <QtCore>
class sphRecognizer : public QThread
{
Q_OBJECT
public:
sphRecognizer(int argc, char **argv);
~sphRecognizer(void);
signals:
void recognized(const QString& hyp);
public:
void run(void);
private:
ps_decoder_t *ps;
cmd_ln_t *config;
};
//
// sphRecognizer.h ends here
From pocket sphinx we include an attribute that is the decoder itself, from sphonxbase, we include the command line configuration parser that will be able to retrieve and use our language model and our dictionary. This thread emits a signal, whenever a word has been recognized by the decoder. Here is its definition.
// Version: $Id$
//
//
// Commentary:
//
//
// Change Log:
//
//
// Code:
#include "sphRecognizer.h"
static const arg_t cont_args_def[] = {
POCKETSPHINX_OPTIONS,
{ "-argfile",
ARG_STRING,
NULL,
"Argument file giving extra arguments." },
{ "-adcdev",
ARG_STRING,
NULL,
"Name of audio device to use for input." },
{ "-infile",
ARG_STRING,
NULL,
"Audio file to transcribe." },
{ "-time",
ARG_BOOLEAN,
"no",
"Print word times in file transcription." },
CMDLN_EMPTY_OPTION
};
sphRecognizer::sphRecognizer(int argc, char **argv)
{
config = cmd_ln_parse_r(NULL, cont_args_def, argc, argv, FALSE);
if (config == NULL)
qFatal("Unable to parse config");
ps = ps_init(config);
if (ps == NULL)
qFatal("Unable to initialize decoder");
}
sphRecognizer::~sphRecognizer(void)
{
ps_free(ps);
}
void sphRecognizer::run(void)
{
ad_rec_t *ad;
int16 adbuf[4096];
int32 k, ts, rem;
char const *hyp;
char const *uttid;
cont_ad_t *cont;
char word[256];
if ((ad = ad_open_dev(cmd_ln_str_r(config, "-adcdev"),
(int)cmd_ln_float32_r(config, "-samprate"))) == NULL)
E_FATAL("Failed to open audio device\n");
if ((cont = cont_ad_init(ad, ad_read)) == NULL)
E_FATAL("Failed to initialize voice activity detection\n");
if (ad_start_rec(ad) < 0)
E_FATAL("Failed to start recording\n");
if (cont_ad_calib(cont) < 0)
E_FATAL("Failed to calibrate voice activity detection\n");
forever {
printf("READY....\n");
fflush(stdout);
fflush(stderr);
/* Wait data for next utterance */
while ((k = cont_ad_read(cont, adbuf, 4096)) == 0)
msleep(100);
if (k < 0)
E_FATAL("Failed to read audio\n");
if (ps_start_utt(ps, NULL) < 0)
E_FATAL("Failed to start utterance\n");
ps_process_raw(ps, adbuf, k, FALSE, FALSE);
printf("Listening...\n");
fflush(stdout);
ts = cont->read_ts;
for (;;) {
if ((k = cont_ad_read(cont, adbuf, 4096)) < 0)
E_FATAL("Failed to read audio\n");
if (k == 0) {
if ((cont->read_ts - ts) > DEFAULT_SAMPLES_PER_SEC)
break;
}
else {
ts = cont->read_ts;
}
rem = ps_process_raw(ps, adbuf, k, FALSE, FALSE);
if ((rem == 0) && (k == 0))
msleep(20);
}
ad_stop_rec(ad);
while (ad_read(ad, adbuf, 4096) >= 0);
cont_ad_reset(cont);
printf("Stopped listening, please wait...\n");
fflush(stdout);
ps_end_utt(ps);
hyp = ps_get_hyp(ps, NULL, &uttid);
printf("%s: %s\n", uttid, hyp);
fflush(stdout);
emit recognized(QString(hyp));
if (hyp) {
sscanf(hyp, "%s", word);
if (strcmp(word, "goodbye") == 0)
break;
}
if (ad_start_rec(ad) < 0)
E_FATAL("Failed to start recording\n");
}
cont_ad_close(cont);
ad_close(ad);
}
//
// sphRecognizer.cpp ends here
A thread in Qt is started by the start() method which calls itself the run() method, that may loop forever as it is the case in our example (notice the forever keyword). The idea is as follows: the audio stream is continuously recorded until a silence occur. Then the recognizer analyses the obtained waveform to match words from our dictionary.
The final step step is to glue alltogether. This is done within our main QML file.
//Version: $Id$
//
//
//Commentary:
//
//
//Change Log:
//
//
//Code:
import QtQuick 2.0
Rectangle {
width: 320;
height: 480;
color: "#343434"
Rectangle {
anchors.centerIn: parent;
width: 200;
height: 200;
radius: 30;
color: "transparent";
border.width: 4;
border.color: "white";
SideRect {
id: leftRect;
anchors { verticalCenter: parent.verticalCenter; horizontalCenter: parent.left }
text: "Left";
}
SideRect {
id: rightRect;
anchors { verticalCenter: parent.verticalCenter; horizontalCenter: parent.right }
text: "Right";
}
SideRect {
id: topRect;
anchors { verticalCenter: parent.top; horizontalCenter: parent.horizontalCenter }
text: "Top"
}
SideRect {
id: bottomRect;
anchors { verticalCenter: parent.bottom; horizontalCenter: parent.horizontalCenter }
text: "Bottom";
}
Rectangle {
id: focusRect
property string text
x: 62;
y: 75;
width: 75;
height: 50;
radius: 6;
border.width: 4;
border.color: "white";
color: "firebrick";
Behavior on x {
NumberAnimation { easing.type: Easing.OutElastic; easing.amplitude: 3.0; easing.period: 2.0; duration: 300 }
}
Behavior on y {
NumberAnimation { easing.type: Easing.OutElastic; easing.amplitude: 3.0; easing.period: 2.0; duration: 300 }
}
Text {
id: focusText
text: focusRect.text
anchors.centerIn: parent
color: "white"
font.pixelSize: 16; font.bold: true
Behavior on text {
SequentialAnimation {
NumberAnimation { target: focusText; property: "opacity"; to: 0; duration: 150 }
NumberAnimation { target: focusText; property: "opacity"; to: 1; duration: 150 }
}
}
}
}
}
Connections {
target: recognizer;
onRecognized: {
if(hyp === "RIGHT") {
focusRect.x = rightRect.x;
focusRect.y = rightRect.y;
focusRect.text = rightRect.text;
}
if(hyp === "TOP") {
focusRect.x = topRect.x;
focusRect.y = topRect.y;
focusRect.text = topRect.text;
}
if(hyp === "LEFT") {
focusRect.x = leftRect.x;
focusRect.y = leftRect.y;
focusRect.text = leftRect.text;
}
if(hyp === "BOTTOM") {
focusRect.x = bottomRect.x;
focusRect.y = bottomRect.y;
focusRect.text = bottomRect.text;
}
}
}
}
//
//main.qml ends here
Note the Connections item that allows to respond to signals for an object, in our case, the recognizer property that we have bound from the C++ side of our program.